- Published on
Apache Spark
- Authors

- Author
- Hang DONG
Index
Intro to Apache Spark
Apache Spark is a fast and general engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads (only for spark 3), MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing. It's fast. "Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk". DAG Engine (directed acyclic graph) optimizes workflows. Spark introduces the concept of an RDD (Resilient Distributed Dataset), an immutable fault-tolerant, distributed collection of objects that can be operated on in parallel. An RDD can contain any type of object and is created by loading an external dataset or distributing a collection from the driver program. Each RDD is split into multiple partitions (similar pattern with smaller sets), which may be computed on different nodes of the cluster.
RDD means:
- Resilient – capable of rebuilding data on failure
- Distributed – distributes data among various nodes in cluster
- Dataset – collection of partitioned data with values

Core Concepts in Spark
Job: A piece of code which reads some input from HDFS or local, performs some computation on the data and writes some output data.Stages: Jobs are divided into stages. Stages are classified as a Map or reduce stages (Its easier to understand if you have worked on Hadoop and want to correlate). Stages are divided based on computational boundaries, all computations (operators) cannot be Updated in a single Stage. It happens over many stages.Tasks: Each stage has some tasks, one task per partition. One task is executed on one partition of data on one executor (machine).DAG: DAG stands for Directed Acyclic Graph, in the present context its a DAG of operators.Executor: The process responsible for executing a task.Master: The machine on which the Driver program runsSlave: The machine on which the Executor program runs
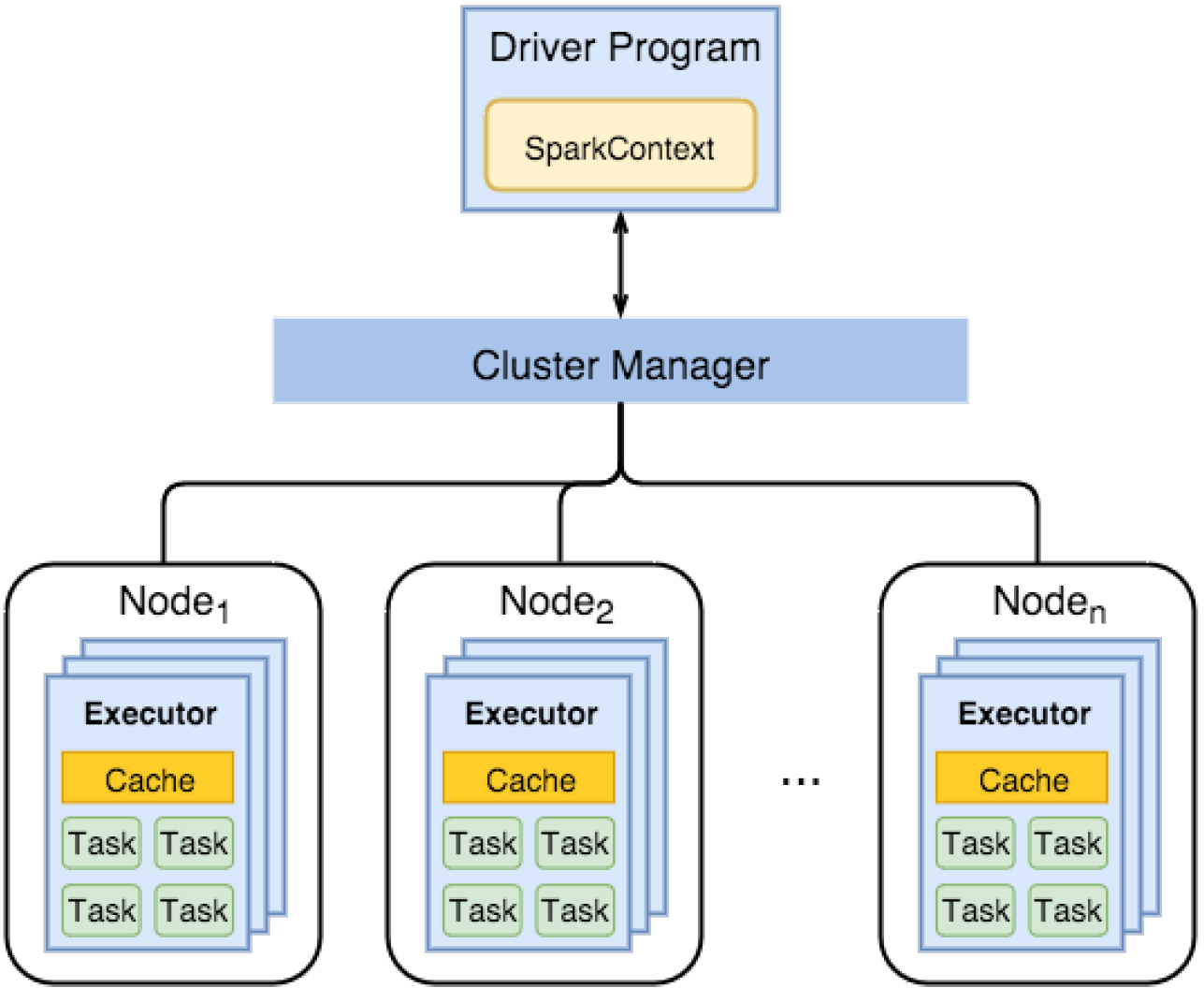
Spark Components
- Spark Driver
- A separate process to execute user applications
- Creates SparkContext to schedule jobs execution and negotiate with cluster manager
- Executors
- Run tasks scheduled by driver
- Store computation results in memory, on disk or off-heap
- interact with storage systems
- Cluster Manager
- Mesos
- YARN
- Spark Standalone
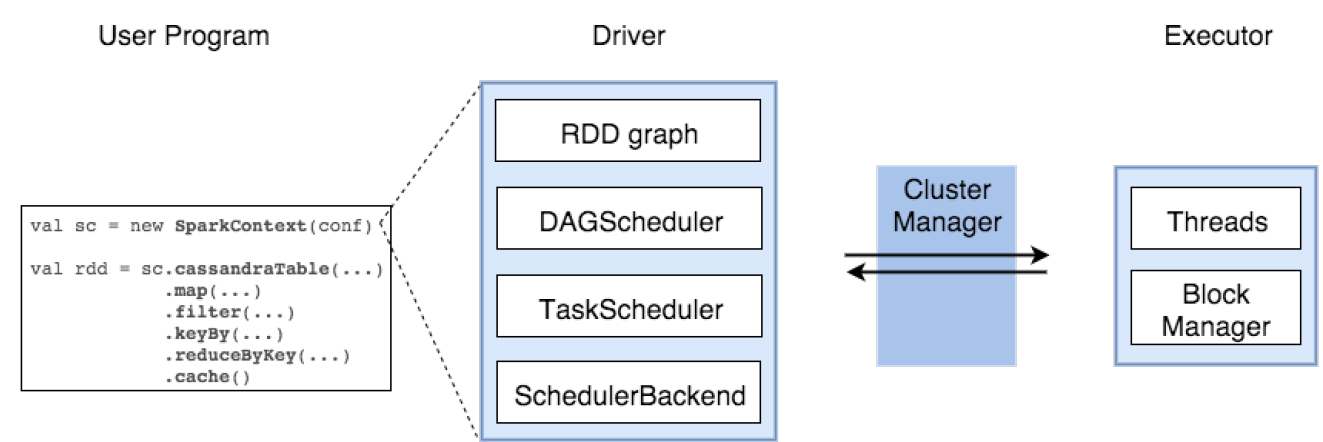
SparkContext
represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that clusterDAGScheduler
computes a DAG of stages for each job and submits them to TaskScheduler determines preferred locations for tasks (based on cache status or shuffle files locations) and finds minimum schedule to run the jobsTaskScheduler
responsible for sending tasks to the cluster, running them, retrying if there are failures, and mitigating stragglersSchedulerBackend
backend interface for scheduling systems that allows plugging in different implementations( Mesos, YARN, Standalone, local)BlockManager
provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap)
How Spark works?
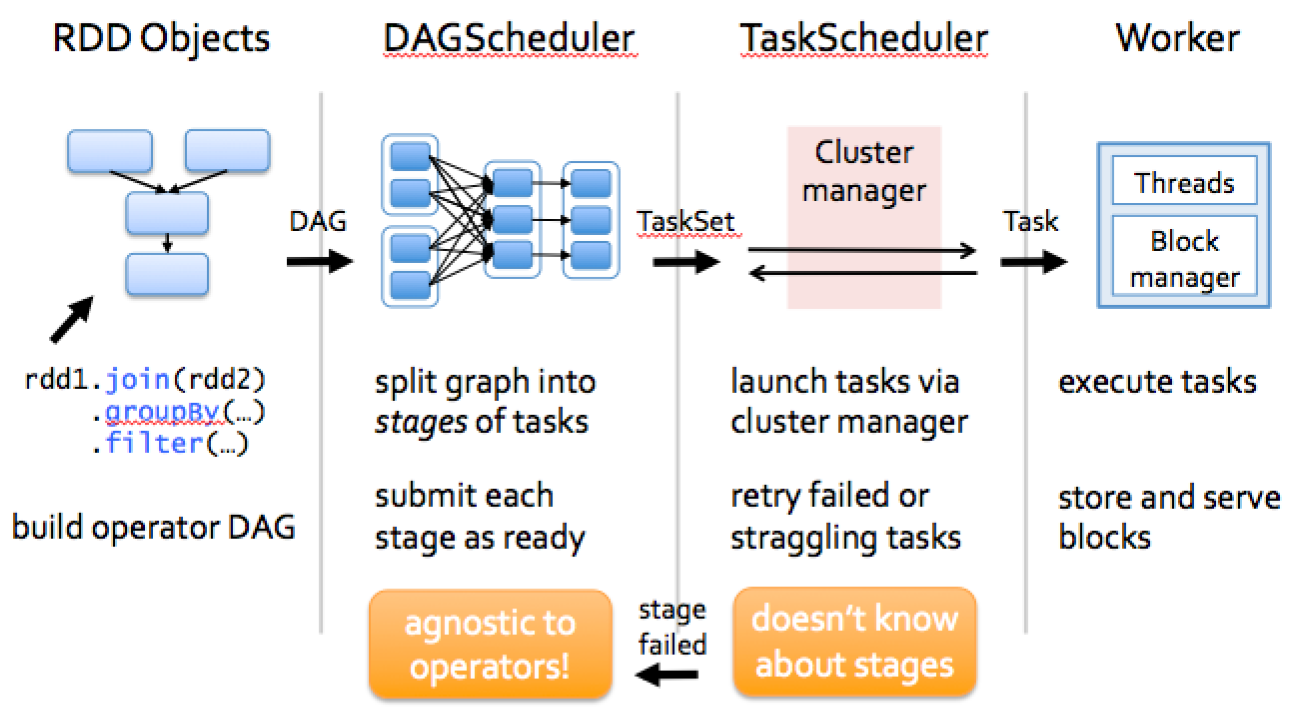
Spark Operations
There are two main types of Spark operations: Transformations and Actions.
Spark Transformations
Spark RDD Transformations are functions that take an RDD as the input and produce one or many RDDs as the output. They do not change the input RDD (since RDDs are immutable and hence one cannot change it), but always produce one or more new RDDs by applying the computations they represent e.g. Map(), filter(), reduceByKey() etc.
Now there is a point to be noted here and that is when you apply the transformation on any RDD it will not perform the operation immediately. It will create a DAG(Directed Acyclic Graph) using the applied operation, source RDD and function used for transformation. And it will keep on building this graph using the references till you apply any action operation on the last lined up RDD. That is why the transformation in Spark are lazy.
Transformations construct a new RDD from a previous one. For example, one common transformation is filtering data that matches a predicate.
There are two types of transformations:
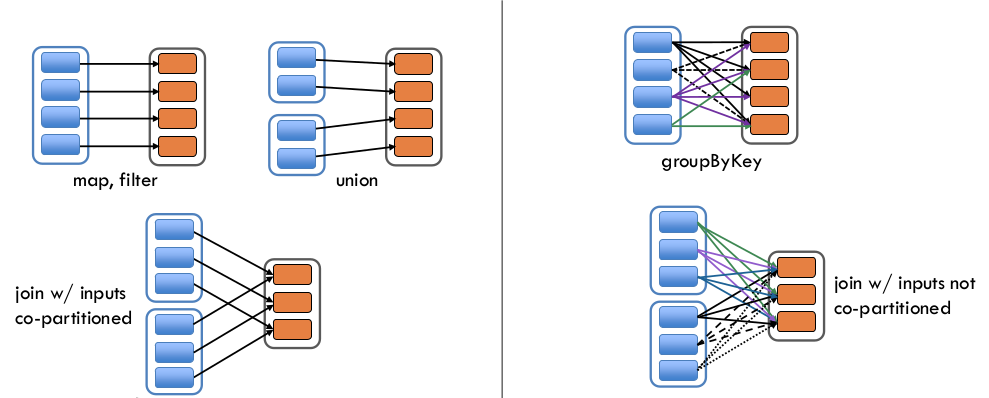
Narrow transformation— In Narrow transformation, all the elements that are required to compute the records in single partition live in the single partition of parent RDD. A limited subset of partition is used to calculate the result. Narrow transformations are the result ofmap(),filter().Wide transformation— In wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD. Wide transformations are the result ofgroupbyKeyandreducebyKey.

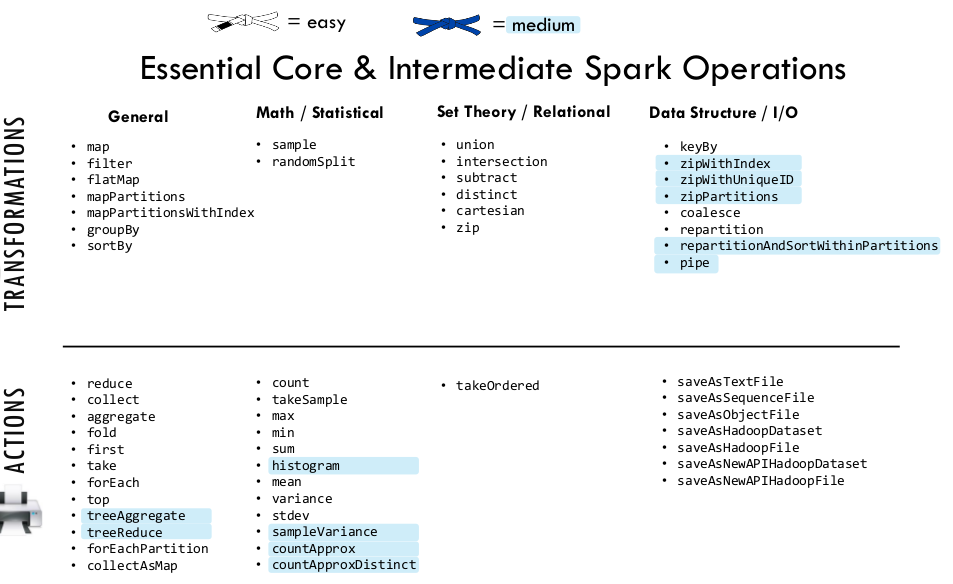
Spark Actions
Actions, on the other hand, compute a result based on an RDD, and either return it to the driver program or save it to an external storage system (e.g., HDFS). Action is one of the ways of sending data from Executer to the driver. Executors are agents that are responsible for executing a task. While the driver is a JVM process that coordinates workers and execution of the task. Spark Paired RDDs are nothing but RDDs containing a key-value pair. Basically, key-value pair (KVP) consists of a two linked data item in it. Here, the key is the identifier, whereas value is the data corresponding to the key value. Moreover, Spark operations work on RDDs containing any type of objects. However key-value pair RDDs attains few special operations in it. Such as, distributed “shuffle” operations, grouping or aggregating the elements by a key.
- map and flatMap operations
Returns a new RDD by applying a function to each element of this RDD. - groupBy operation
- filter operation
Returns a new dataset formed by selecting those elements of the source on which func returns true.
References
https://hackmd.io/@firasj/ryoMFdkCi
https://blog.knoldus.com/deep-dive-into-apache-spark-transformations-and-action/
https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/